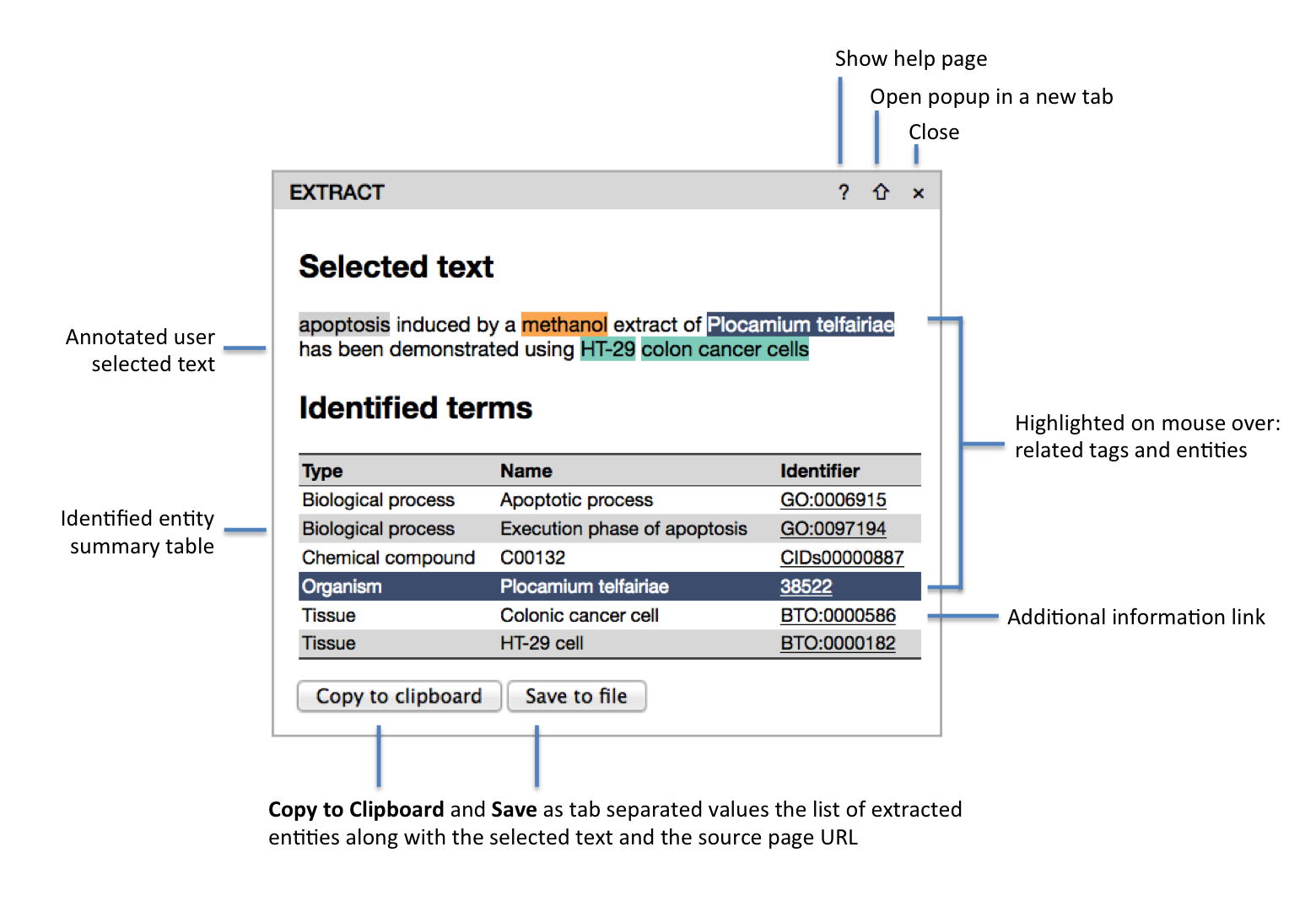
EXTRACT identifies genes/proteins, chemical compounds, organisms, environments, tissues, diseases, phenotypes and Gene Ontology terms mentioned in a given piece of text and maps them to their corresponding ontology/taxonomy entries.
Bookmarklet: To install please Drag and Drop the following link in your Bookmark Bar:
EXTRACT

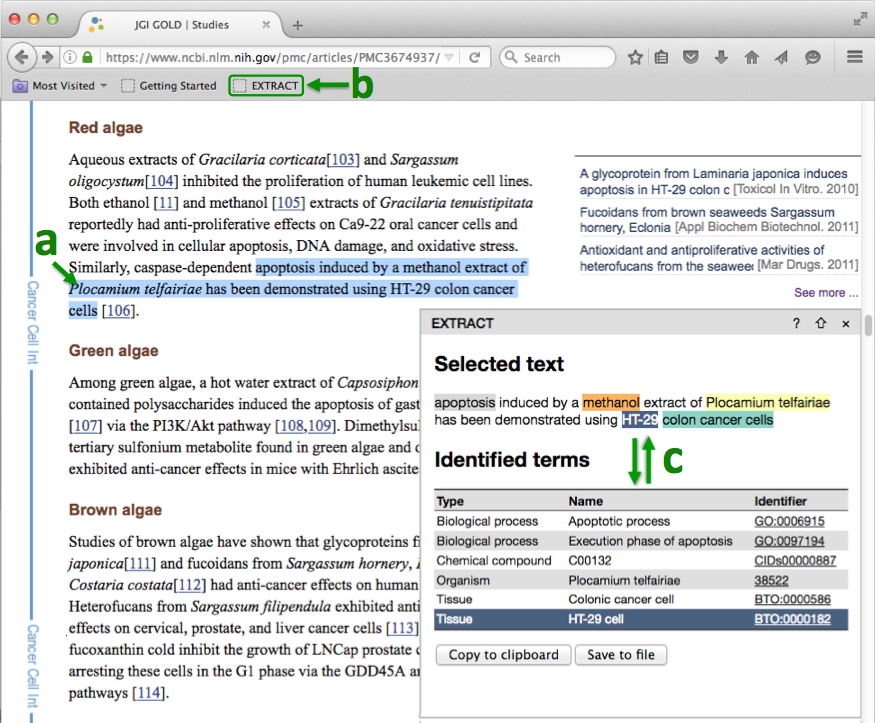
Selected-text-based extraction: a. select a piece of text of interest in a
web page and then b. click on the bookmarklet. c. A pop-up, such as the one
shown on the left image below, will appear (supported browsers:
Chrome,
Firefox,
Safari,
Opera,
Internet Explorer).
By hovering the mouse cursor over the text tags or the table rows you can
visually inspect which words have been identified as which entities. To
easily collect extracted annotations, e.g. for use in an Excel spreadsheet, direct
Copy to clipboard and Save to file (tab-delimited) are supported.
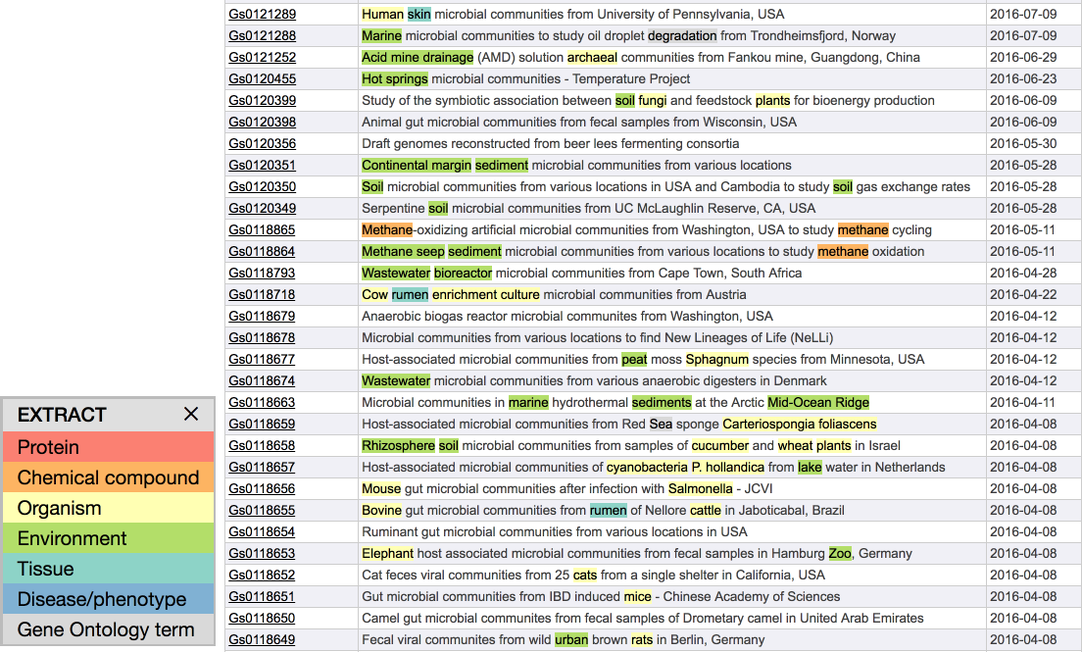
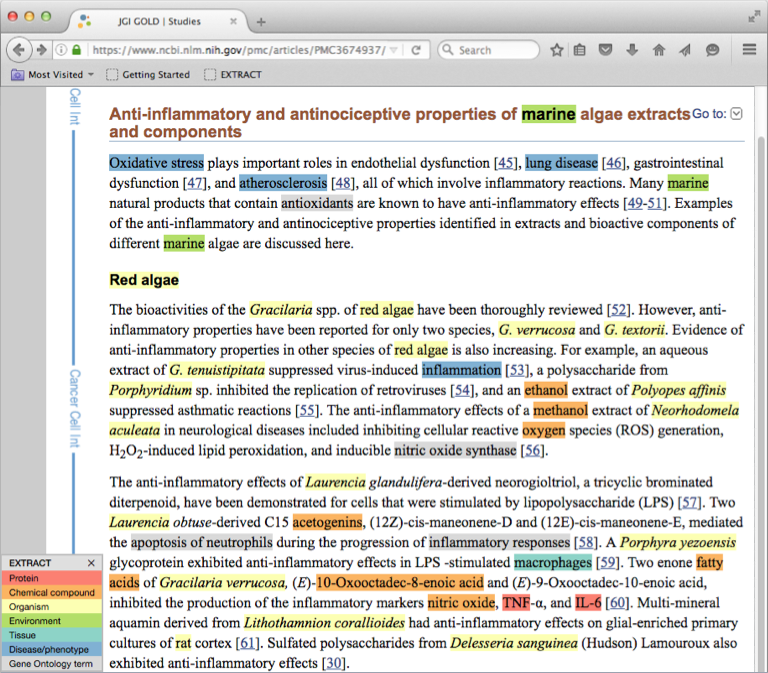
Full page tagging: if you would like to get a quick and visual overview of the
web page sections containing environmental context information just click on the
bookmarklet without having selected any pieces of text. The complete page
will be tagged and identified entities will be highlighted (see the right image
below and the
example).
Read more:
-
EXTRACT 2.0: text-mining-assisted interactive annotation of biomedical named entities and ontology terms
. Pafilis E, Bērziņš R, Jensen LJ.
(2017) bioRχiv preprint,
 [HTML]
[HTML]
-
EXTRACT: interactive extraction of environment metadata and term suggestion for
metagenomic sample annotation. Pafilis E, Buttigieg PL, Ferrell B, et al.
(2016) Database, baw005
 [HTML]
[HTML]
- The backend-tagger and its detailed API are described in: Real-time tagging of biomedical entities. Pafilis,E. and Jensen,L.J. (2016) bioRxiv Preprint
- Cross-domain and interdisciplinary use of the real-time tagger: One tagger, many uses - Illustrating the power of ontologies in dictionary-based named entity recognition. Jensen,L.J. (2016) bioRxiv Preprint
Please find below:
- Practical tips on how to use EXTRACT
- Curation assistance points
- Technical points and troubleshooting cases
- Using EXTRACT within other resources
Points in blue are a good starting point as they provide you with basic information about the EXTRACT bookmarklet, such as how to install and use the bookmarklet, and the EXTRACT popup description. Some points about record annotation with standardized metadata are listed afterwards (in green), followed by troubleshooting cases (in orange). Information on how to use EXTRACT within other resources can be found at the end (in purple).